Vor einiger Zeit habe ich eine Liste von Youtube-Shorts über Petrinetze begonnen. Ich habe mich sehr über die folgende Rückmeldung von Olivier Meier gefreut, welche ich im Sinne der Eigenwerbung keinem vorenthalten will:
“Ich muss sagen, das ist wirklich der beste Inhalt den man zu Petrinetzen finden kann, vielen Dank dafür. Kurz, trocken, amüsant, aufschlussreich. Köstliche Playlist!“
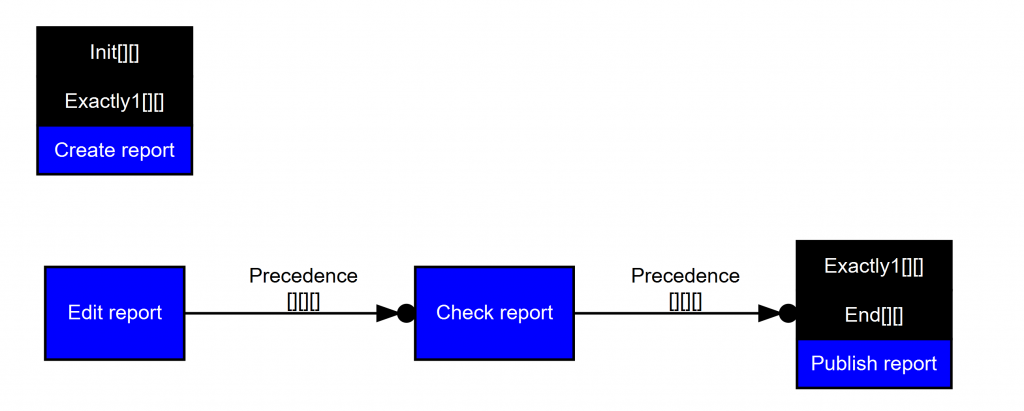
Beim klassischen Process Mining wird gesagt, welche Schritte in welcher Reihenfolge ausgeführt werden können. Beim Declarative Process Mining ist alles erlaubt, was nicht explizit verboten ist.
Es soll untersucht werden, wie stark sich der klassische und der deklarative Ansatz in der Praxis tatsächlich unterscheiden. Für deklarative Prozessmodelle aus der Literatur sollen Petrinetz- oder YAWL-Modelle erstellt werden, welche dieselben Ausführungsreihenfolgen erlauben.
Literatur
Aalst, W. M. P. van der, H. T. de Beer, and B. F. van Dongen. ‘Process Mining and Verification of Properties: An Approach Based on Temporal Logic’. In On the Move to Meaningful Internet Systems 2005: CoopIS, DOA, and ODBASE, edited by Robert Meersman and Zahir Tari, 130–47. Lecture Notes in Computer Science. Berlin, Heidelberg: Springer, 2005. https://doi.org/10.1007/11575771_11.
Aalst, W. M. P. van der, M. Pesic, and H. Schonenberg. ‘Declarative Workflows: Balancing between Flexibility and Support’. Computer Science – Research and Development 23, no. 2 (1 May 2009): 99–113. https://doi.org/10.1007/s00450-009-0057-9.
Bauer, Andreas, Martin Leucker, and Christian Schallhart. ‘C.: Comparing LTL Semantics for Runtime Verification’. Journal of Logic and Computation, 2008.
Broucke, Seppe K. L. M. vanden, Jan Vanthienen, and Bart Baesens. ‘Declarative Process Discovery with Evolutionary Computing’. In 2014 IEEE Congress on Evolutionary Computation (CEC), 2412–19, 2014. https://doi.org/10.1109/CEC.2014.6900293.
Burattin, Andrea, Fabrizio M. Maggi, Wil M.P. van der Aalst, and Alessandro Sperduti. ‘Techniques for a Posteriori Analysis of Declarative Processes’. In 2012 IEEE 16th International Enterprise Distributed Object Computing Conference, 41–50, 2012. https://doi.org/10.1109/EDOC.2012.15.
Burattin, Andrea, Fabrizio M. Maggi, and Alessandro Sperduti. ‘Conformance Checking Based on Multi-Perspective Declarative Process Models’. Expert Systems with Applications 65 (15 December 2016): 194–211. https://doi.org/10.1016/j.eswa.2016.08.040.
Ciccio, Claudio Di, and Massimo Mecella. ‘On the Discovery of Declarative Control Flows for Artful Processes’. ACM Transactions on Management Information Systems 5, no. 4 (23 January 2015): 24:1-24:37. https://doi.org/10.1145/2629447.
De Masellis, Riccardo, Chiara Di Francescomarino, Chiara Ghidini, and Fabrizio M. Maggi. ‘Declarative Process Models: Different Ways to Be Hierarchical’. In Service-Oriented Computing, edited by Quan Z. Sheng, Eleni Stroulia, Samir Tata, and Sami Bhiri, 104–19. Lecture Notes in Computer Science. Cham: Springer International Publishing, 2016. https://doi.org/10.1007/978-3-319-46295-0_7.
Debois, Søren, Thomas T. Hildebrandt, Paw Høvsgaard Laursen, and Kenneth Ry Ulrik. ‘Declarative Process Mining for DCR Graphs’. In Proceedings of the Symposium on Applied Computing, 759–64. SAC ’17. New York, NY, USA: Association for Computing Machinery, 2017. https://doi.org/10.1145/3019612.3019622.
Di Ciccio, Claudio, Fabrizio Maria Maggi, Marco Montali, and Jan Mendling. ‘Ensuring Model Consistency in Declarative Process Discovery’. In Business Process Management, edited by Hamid Reza Motahari-Nezhad, Jan Recker, and Matthias Weidlich, 144–59. Lecture Notes in Computer Science. Cham: Springer International Publishing, 2015. https://doi.org/10.1007/978-3-319-23063-4_9.
———. ‘Resolving Inconsistencies and Redundancies in Declarative Process Models’. Information Systems 64 (1 March 2017): 425–46. https://doi.org/10.1016/j.is.2016.09.005.
Di Ciccio, Claudio, and Massimo Mecella. ‘A Two-Step Fast Algorithm for the Automated Discovery of Declarative Workflows’. In 2013 IEEE Symposium on Computational Intelligence and Data Mining (CIDM), 135–42, 2013. https://doi.org/10.1109/CIDM.2013.6597228.
Grando, M. A., Wil M. P. van der Aalst, and Ronny S. Mans. ‘Reusing a Declarative Specification to Check the Conformance of Different CIGs’. In Business Process Management Workshops, edited by Florian Daniel, Kamel Barkaoui, and Schahram Dustdar, 188–99. Lecture Notes in Business Information Processing. Berlin, Heidelberg: Springer, 2012. https://doi.org/10.1007/978-3-642-28115-0_19.
Grando, M. A., M. H. Schonenberg, and W. van der Aalst. ‘Semantic-Based Conformance Checking of Computer Interpretable Medical Guidelines’. In Biomedical Engineering Systems and Technologies, edited by Ana Fred, Joaquim Filipe, and Hugo Gamboa, 285–300. Communications in Computer and Information Science. Berlin, Heidelberg: Springer, 2013. https://doi.org/10.1007/978-3-642-29752-6_21.
Leoni, Massimiliano de, Fabrizio M. Maggi, and Wil M. P. van der Aalst. ‘An Alignment-Based Framework to Check the Conformance of Declarative Process Models and to Preprocess Event-Log Data’. Information Systems 47 (1 January 2015): 258–77. https://doi.org/10.1016/j.is.2013.12.005.
Leoni, Massimiliano de, Fabrizio Maria Maggi, and Wil M. P. van der Aalst. ‘Aligning Event Logs and Declarative Process Models for Conformance Checking’. In Business Process Management, edited by Alistair Barros, Avigdor Gal, and Ekkart Kindler, 82–97. Lecture Notes in Computer Science. Berlin, Heidelberg: Springer, 2012. https://doi.org/10.1007/978-3-642-32885-5_6.
Maggi, Fabrizio M., R. P. Jagadeesh Chandra Bose, and Wil M. P. van der Aalst. ‘Efficient Discovery of Understandable Declarative Process Models from Event Logs’. In Advanced Information Systems Engineering, edited by Jolita Ralyté, Xavier Franch, Sjaak Brinkkemper, and Stanislaw Wrycza, 270–85. Lecture Notes in Computer Science. Berlin, Heidelberg: Springer, 2012. https://doi.org/10.1007/978-3-642-31095-9_18.
Maggi, Fabrizio M., Arjan J. Mooij, and Wil M.P. van der Aalst. ‘User-Guided Discovery of Declarative Process Models’. In 2011 IEEE Symposium on Computational Intelligence and Data Mining (CIDM), 192–99, 2011. https://doi.org/10.1109/CIDM.2011.5949297.
Maggi, Fabrizio Maria. ‘Discovering Metric Temporal Business Constraints from Event Logs’. In Perspectives in Business Informatics Research, edited by Björn Johansson, Bo Andersson, and Nicklas Holmberg, 261–75. Lecture Notes in Business Information Processing. Cham: Springer International Publishing, 2014. https://doi.org/10.1007/978-3-319-11370-8_19.
Maggi, Fabrizio Maria, Claudio Di Ciccio, Chiara Di Francescomarino, and Taavi Kala. ‘Parallel Algorithms for the Automated Discovery of Declarative Process Models’. Information Systems, Special Issue on papers presented in the 20th IEEE International Enterprise Distributed Object Computing1 Conference, EDOC 2016, 74 (1 May 2018): 136–52. https://doi.org/10.1016/j.is.2017.12.002.
Maggi, Fabrizio Maria, Marco Montali, Michael Westergaard, and Wil M. P. van der Aalst. ‘Monitoring Business Constraints with Linear Temporal Logic: An Approach Based on Colored Automata’. In Business Process Management, 132–47. Springer, Berlin, Heidelberg, 2011. https://doi.org/10.1007/978-3-642-23059-2_13.
Montali, Marco, Federico Chesani, Paola Mello, and Fabrizio M. Maggi. ‘Towards Data-Aware Constraints in Declare’. In Proceedings of the 28th Annual ACM Symposium on Applied Computing, 1391–96. SAC ’13. New York, NY, USA: Association for Computing Machinery, 2013. https://doi.org/10.1145/2480362.2480624.
Montali, Marco, Fabrizio M. Maggi, Federico Chesani, Paola Mello, and Wil M. P. van der Aalst. ‘Monitoring Business Constraints with the Event Calculus’. ACM Transactions on Intelligent Systems and Technology 5, no. 1 (3 January 2014): 17:1-17:30. https://doi.org/10.1145/2542182.2542199.
Montali, Marco, Maja Pesic, Wil M. P. van der Aalst, Federico Chesani, Paola Mello, and Sergio Storari. ‘Declarative Specification and Verification of Service Choreographies’. ACM Transactions on the Web 4, no. 1 (29 January 2010): 3:1-3:62. https://doi.org/10.1145/1658373.1658376.
Pesic, Maja, Helen Schonenberg, and Wil M.P. van der Aalst. ‘DECLARE: Full Support for Loosely-Structured Processes’. In 11th IEEE International Enterprise Distributed Object Computing Conference (EDOC 2007), 287–287, 2007. https://doi.org/10.1109/EDOC.2007.14.
Pnueli, Amir. ‘The Temporal Logic of Programs’. In 18th Annual Symposium on Foundations of Computer Science (Sfcs 1977), 46–57, 1977. https://doi.org/10.1109/SFCS.1977.32.
Rovani, Marcella, Fabrizio M. Maggi, Massimiliano de Leoni, and Wil M. P. van der Aalst. ‘Declarative Process Mining in Healthcare’. Expert Systems with Applications 42, no. 23 (15 December 2015): 9236–51. https://doi.org/10.1016/j.eswa.2015.07.040.
Schönig, Stefan, Andreas Rogge-Solti, Cristina Cabanillas, Stefan Jablonski, and Jan Mendling. ‘Efficient and Customisable Declarative Process Mining with SQL’. In Advanced Information Systems Engineering, edited by Selmin Nurcan, Pnina Soffer, Marko Bajec, and Johann Eder, 290–305. Lecture Notes in Computer Science. Cham: Springer International Publishing, 2016. https://doi.org/10.1007/978-3-319-39696-5_18.
Zugal, Stefan, Pnina Soffer, Cornelia Haisjackl, Jakob Pinggera, Manfred Reichert, and Barbara Weber. ‘Investigating Expressiveness and Understandability of Hierarchy in Declarative Business Process Models’. Software & Systems Modeling 14, no. 3 (1 July 2015): 1081–1103. https://doi.org/10.1007/s10270-013-0356-2.
Die Notwendigkeit, physische und virtuelle IT-Komponenten systematisch in einer Art Configuration Management Database zu erfassen, hat durch die Entwicklung von Cloud-Services, Software as a Service, etc. weiter zugenommen. Ein Aufsatz von Corcho et al – s. u. – greift dieses Thema auf und entwickelt eine Ontologie für dieses Thema.
Die Aufgabe besteht darin, diesen Ansatz durch Anwendung auf einen konkreten Fall zu validieren. Bei kleineren Szenarien, wie etwa der für die LV IT-Service-Management erdachten WAM-GmbH, eignet sich dieses Thema für eine Bachelorarbeit. Wenn dieses Thema mit einem Unternehmen und einem echten Anwendungsfall kombiniert wird, ist es auch als Masterprojekt bzw. Masterarbeit geeignet.
Voraussetzung für die Bearbeitung dieses Themas ist unter anderem die Arbeit mit dem Ontologie-Editor Protégé. Wenn das Thema als Masterprojekt bzw. Masterarbeit bearbeitet werden soll, so kommt die Arbeit mit Apache Jena dazu.
Es besteht die Möglichkeit, mit den Autoren des Artikels in Madrid zusammenzuarbeiten. In diesem Falle wäre ggf. sinnvoll, auf Englisch zu schreiben.
@InProceedings{10.1007/978-3-030-88361-4_26, author=”Corcho, Oscar and Chaves-Fraga, David and Toledo, Jhon and Arenas-Guerrero, Juli{\’a}n and Badenes-Olmedo, Carlos and Wang, Mingxue and Peng, Hu and Burrett, Nicholas and Mora, Jos{\’e} and Zhang, Puchao”, editor=”Hotho, Andreas and Blomqvist, Eva and Dietze, Stefan and Fokoue, Achille and Ding, Ying and Barnaghi, Payam and Haller, Armin and Dragoni, Mauro and Alani, Harith”, title=”A High-Level Ontology Network for ICT Infrastructures”, booktitle=”The Semantic Web — ISWC 2021″, year=”2021″, publisher=”Springer International Publishing”, address=”Cham”, pages=”446–462″, abstract=”The ICT infrastructures of medium and large organisations that offer ICT services (infrastructure, platforms, software, applications, etc.) are becoming increasingly complex. Nowadays, these environments combine all sorts of hardware (e.g., CPUs, GPUs, storage elements, network equipment) and software (e.g., virtual machines, servers, microservices, services, products, AI models). Tracking, understanding and acting upon all the data produced in the context of such environments is hence challenging. Configuration management databases have been so far widely used to store and provide access to relevant information and views on these components and on their relationships. However, different databases are organised according to different schemas. Despite existing efforts in standardising the main entities relevant for configuration management, there is not yet a core set of ontologies that describes these environments homogeneously, and which can be easily extended when new types of items appear. This paper presents an ontology network created with the purpose of serving as an initial step towards an homogeneous representation of this domain, and which has been already used to produce a knowledge graph for a large ICT company.”, isbn=”978-3-030-88361-4″ }
There is a new series of videos on ITIL 4 on Youtube. It is targeted at IT managers who wonder how to use ITIL 4 to the advantage of their organisation. This series is not a systematic course about the whole ITIL 4 framework. The focus will be on topics like value stream modeling and business process automation.
There is a new video series on Business Process Automation. The previous video series is on the Business Process Management System YAWL. It focuses on using the system and is over 90% hands on tutorials. This new series tries to fill the gap about more general practical tips on Business Process Automation that are independent of YAWL.
Process Mining ist eine Big Data Technologie, die aus Logdaten von IT-Systemen Kennzahlen, Animationen und Prozessmodelle erzeugen kann, die für das Verständnis und die Optimierung von Geschäftsprozessen wesentlich sind. Voraussetzung für eine Thesis in diesem Bereich ist das Vorhandensein von Daten, die idealerweise aus einem Unternehmen kommen sollten.
Video:
Literatur:
@book{aalst_process_2016, address = {New York, NY}, edition = {2nd ed. 2016}, title = {Process {Mining}: {Data} {Science} in {Action}}, isbn = {978-3-662-49850-7}, shorttitle = {Process {Mining}}, language = {Englisch}, publisher = {Springer}, author = {Aalst, Wil M. P. van der}, month = apr, year = {2016} }